Population Synthesis
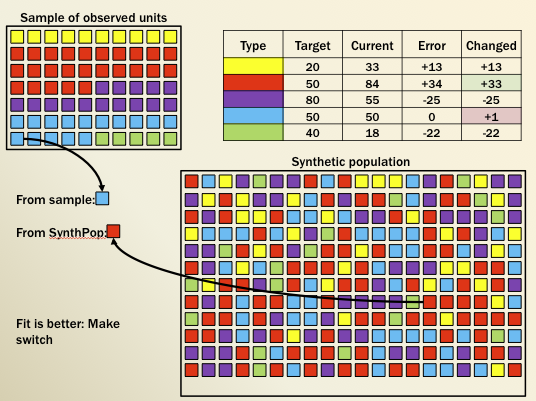
The population synthesizer software was developed at HBA. It works by combining a trial population of households and altering it by switching new possible households in; if the match with the targets improves, the new household is kept. Key notes are that the synthesizer is capable of handling multiple nested geographies, of matching categorical totals or averages, and of weighting the possible targets. This last feature is useful if some targets are held to be more important than others or if the scales differ (such as with an average income category).
The preparation of a synthetic population needs two elements: samples which are the individual household records to be used and targets which are the control totals for geographies in the model system, such as zones. The software works to identify a list of units whose aggregate attribute values match a pre-specified set of corresponding target values. This list forms a synthetic population of such units consistent with the target values. Each unit included in this list is drawn from a sample of such units, with the potential that any particular unit in the sample is included in the list 0, 1 or more times as appropriate.
The software proceeds by iteratively considering adding a unit from the sample to the list, subtracting a unit from the list, or ‘swaps’ where a unit in the list is swapped out and a unit from the sample is swapped in. The match of the list to the target values is scored using a goodness-of-fit function. The list is divided into subgroups, which are commonly used to specify geographic areas known as “zones” which are to contain portions of a population. The process works through the list subgroup by subgroup. For each subgroup first one of the three operations is selected with equal 1/3 probability (add, subtract or swap). In the case of subtract or swap a unit in the subgroup is randomly selected. In the case of add or swap a unit in the sample is randomly selected. The operation is then performed, and the magnitude of the improvement in the goodness-of-fit score is calculated. If the goodness of fit improves the operation is kept. If the goodness of fit gets worse there is a less-than-1.0 probability that the operation will be kept, otherwise the operation will be undone.
It is possible to have the program start with a previously generated list. If no such previously generated list is available, an initial list is generated by randomly selecting enough units at random to reach or exceed target values for just one of the attributes for each subgroup. The decision to keep an operation at any point includes a probabilistic component. Operations that lead to a worse goodness of fit will be more likely to be accepted early in the process than later in the process. This is what is termed a ‘simulated annealing’ algorithm – based on the idea that the program should be getting closer to the best possible match as the number of iterations increases and thus a non-improving swap is more likely to be detrimental rather than advantageous in the search for this best possible match.
The general formula used in the measurement of goodness-of-fit is,
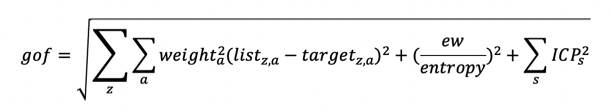
where:


The weight associated with an attribute indicates the relative importance to be placed on achieving a match with regard to that attribute. The formula used to assign the probability of accepting an operation that leads to a worse goodness of fit is:
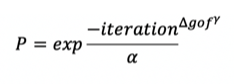

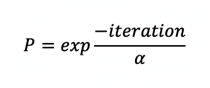
*the number of iterations to be performed by the program is specified by the user as part of the inputs.
The target values for the attributes can be specified for individual subgroups of the population or for combinations of the subgroups. The program proceeds subgroup-by-subgroup in its processing, with the number of iterations within each subgroup for each pass through the entire list of subgroup determined according to the comparative goodness-of-fit for the subgroup. The formula used to establish the number of iterations for a given subgroup is:


The program performs iterations on each subgroup, checking the total number of iterations every time a subgroup is processed, and terminating if the total number of iterations meets or exceeds the specified number of iterations. Upon termination the program reports the overall goodness-of-fit, the goodness of fit for each subgroup and for each target in each subgroup, and the resulting list of units comprising the synthetic population. For more information refer to the Population Synthesizer manual, here.